Linguistic Linked Open Data (LLOD)
What is LD – LOD – LLOD?
In recent years, the modeling of data from linguistic resources with the graph data model Resource Description Framework (RDF), following the paradigm of Linked (Open) Data, has become the prevalent method to create datasets for the Semantic Web. The number of multi-disciplinary datasets of the (Linguistic) Linked Open Data cloud has increased significantly during the last decade [see Gandon, Sabou and Sack 2017, Fig. p. 2].
- LD: Linked Data is the term for «a set of best practices for publishing and connecting structured data on the Web» [Bizer, Heath and Berners-Lee 2009]
- LOD: Linked Open Data designates Linked Data published openly on the Web
- LLOD: Linguistic Linked Open Data refers to the subset of linguistic resources within LOD
The principles of (L)LOD are the following (https://www.w3.org/DesignIssues/LinkedData.html):
- Use URIs as names for things.
- Use HTTP URIs so that people can look up those names.
- When someone looks up a URI, provide useful information, using the standards (RDF, SPARQL).
- Include links to other URIs, so that they can discover more things.
Ad 1: A URI is assigned to every piece of information in a given resource, i.e., every place name in a geographic resource, every entry in a lexicographical dataset, every document in a collection, etc. This makes the information globally identifiable in an unambiguous way.
Ad 2: Any «agent wishing to obtain information about the resource can contact the corresponding web server and retrieve this information using a well-established protocol (HTTP) that also supports different ‘views’ on the same resource. That is, computer agents might request a machine readable format, while web browsers might request a human-readable and browseable view of this information as HTML» [Chiarcos, McCrae et al. 2013].
Ad 3: This requires the use of inter-operable data models established as standards which makes it possible to represent and to query the data (using RDF and SPARQL, respectively).
Ad 4: This creates an interdisciplinary, cross-language network of resources and the information therein: e.g, place names can be linked to authors and documents, lexemes to their senses and to the things they denote, phonetic realizations to lexemes.
RDF (Resource Description Framework)
RDF is a data model that expresses data in a directed (multi-)graph structure. The graph consists of sets of statements in the form of subject-predicate-object-triples. Each subject and object represent a node; the predicate (or property) forms the relation (edge) pointing from the source node (subject) to a target node (object). Nodes and edges are identified with URIs, objects can also be expressed as a string literal [RDF 1.1. Primer, 2014] . To be readable by humans and queryable via SPARQL, RDF data is serialized using a syntax format to express the graph structures (e.g., N-Triples, Turtle, RDF/XML).
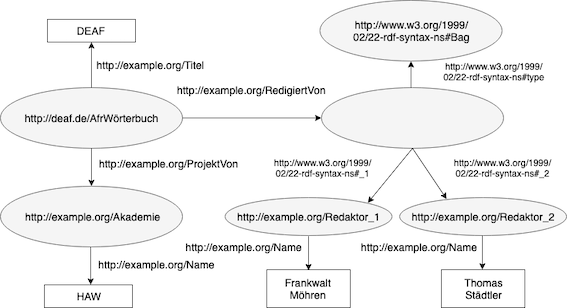
[Fig. 1] An exemplary RDF graph of information concerning the Dictionnaire étymologique de l’ancien français (DEAF, HAdW).

[Fig. 2] The serialization of the graph in Fig. 1 using Turtle notation (Terse RDF Triple Language).

[Fig. 3] The serialization of the Graph in Fig. 1 using RDF/XML notation.
[Fig. 4] The RDF graph of the entry fiel of the DEAF.
Why (L)LOD?
Modeling and publishing data as (L)LOD comes with significant advantages compared to an access via search functions of non-semantic web technologies. This includes
- structural interoperability (cross-resource access by using same format [RDF] and same query language [SPARQL]),
- conceptual interoperability (through shared vocabularies and standard ontologies),
- accessibility (through standard Web protocols [HTTP]), and
- resource integration by means of interlinking.
Describing linguistic data as LD thus enables semantic research across resources and languages, strengthening the integration of the data into a wider, interdisciplinary context on the web. With semantic queries (for, e.g., lexemes, their senses, and concepts referring to artifacts), things and the usage of their designations (in different languages) can be explored in a cultural context without being restricted to the vehicle of a particular language, resource location in the WWW or data format. The integration of resources of different languages and, also, different language stages enables observation through time and space, including, e.g., the grasp of borrowing and word formation processes, gender change, and semantic shift within a large data collection.
For whom (L)LOD?
Although the starting point of our project are historical dictionaries, this technology is suitable for linguistic resources of all timelines. The added value of data as LLOD for all user groups is the enhanced accessibility of the knowledge stored in the machine-readable data. This accessibility is cross-resource, cross-language, interdisciplinary, and able to adapt to the constant increase of LOD datasets. A second benefit is the long-term curation of the data in the form of RDF given that the URIs of linked information (e.g., pointing to a WWW publication of a resource) are persistent and dereferenceable.
Use cases
Use cases 1: A linguist researches the process of semantic shift regarding French juridical terms with respect to the different legal systems in medieval England and France. She starts with a given Old French word for a given thing; she looks up the word in the relevant dictionaries of Old French, Anglo-Norman, Middle-, and Modern French, and finds out when semantic shift happened. But she is also interested in a diachronic onomasiological perspective, i.e., focusing on the thing whose designations changed over time and space. Since she does not know the designations in question, she queries the LLOD for words representing the thing. Given a proper LD modeling of the dictionary data, this is either possible via the definition of the sense or via the mapping of the lexeme/sense to the respective thing as an entity in an ontology, such as DBpedia.
Use case 2: A medical historian researches the Ancient Greek and Roman concept of humorism and its passing on in Western medieval and Renaissance medicine. To find out when physicists started questioning antique authorities, he needs to find the words used to designate concepts of the metabolic processes and to consider the senses of these words. Since he does not know the relevant terms in Old French, Old Gascon, Middle English, Middle High German, medieval Italian, etc., he conducts a SPARQL query for senses that have a definition including the notion of humorism or are mapped to entities in an ontology connected to humorism.
Use case 3: A lexicographer of Middle High German edits an entry of a word that is an Old French loanword. Via a query of this particular etymon across lexicographical resources, she finds out about the Old French word, about its own etymon, about borrowings of the same word in other languages, its adaptation in other languages, words of the same family, etc. This will provide for an overview of the living of the word in a broader (European) context that is significant for the grasp of the word’s comprehension.
How to access (L)LOD?
The query language for RDF data is SPARQL (SPARQL Protocol And RDF Query Language). In a nutshell, a query is composed of five parts [Della Valle and Ceri 2011, p. 307]:
- zero or more declarations of prefixes (to introduce shortcuts for long URIs),
- a query result clause (to specify the form of the result),
- one or more FROM clauses (to define the resources against which the query is executed),
- zero or more WHERE clauses (to specify the conditions of the query) and
- zero or more query modifiers (to define, e.g., the order within the resulting table).
A research question related to use case 1 is: “Which Old French and Old Gascon lexemes exist whose sense is related to juridical terms as expressed by the fact that the sense definition contains the string ‘droit’ (French for “law”). A SPARQL query to find dictionary entries (in a given set of resources) that have senses with this particular sense definition is the following:

[Fig. 5] Example of a SPARQL query.
Explanation:
- line 1: introduction of the prefix
- line 3: as results are specified dictionary entries and their lemmata, concepts and definitions,
- line 5-6: the query is executed against the data of both the DEAF and the Dictionnaire de l’ancien gascon électronique (DAGél, HAdW),
- line 8-15: the conditions are specified; the important detail is the filter for all definitions that include the string ‘droit’ (specified as French)
- line 16: the results are filtered by the entry of the dictionaries.
The following table shows (an extract of) the results ('@pro' meaning that the language of the lemma is identified as Provençal [due to the missing language code for Old Gascon: intermediate solution] = DAGél data, and '@fro' meaning that it is Old French = DEAF data; language codes are defined by ISO 639-3 (https://iso639-3.sil.org/code/fro and https://iso639-3.sil.org/code/pro).
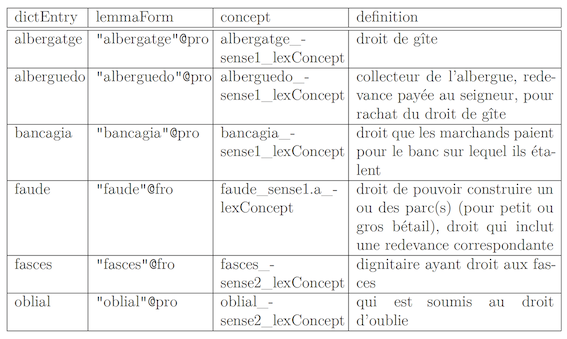
[Fig. 6] Extract of the results of the query in Fig. 5.
Via a SPARQL endpoint, SPARQL queries can be executed.
Literature
Bizer, Christian, Tom Heath and Tim Berners-Lee (2009). „Linked Data – The Story So Far“. In: International Journal on Semantic Web and Information Systems 5,3, p. 1–22.
Chiarcos, Christian, John P. McCrae, Philipp Cimiano and Christiane Fellbaum (2013). „Towards Open Data for Linguistics: Linguistic Linked Data”. In: New Trends of Research in Ontologies and Lexical Resources; DOI:10.1007/978-3-642-31782-8_2.
Della Valle, Emanuele and Stefano Ceri (2011). „Querying the Semantic Web: SPARQL“. In: Handbook of Semantic Web Technologies. Edited by John Domingue, Dieter Fensel and James A. Hendler, Heidelberg (Springer), p. 299–363.
Gandon, Fabien, Marta Sabou and Harald Sack (2017). „Weaving a Web of Linked Resources“. In: Semantic Web Journal 6, p. 1–6.